As the cost of cloud storage and compute continues to fall and internet speeds rise, data engineers are rethinking how data is stored, processed, and analyzed. This shift has led to what we now call the modern data stack: a flexible, scalable, cloud-native approach that replaces traditional monolithic systems.
In this post, we’ll explore key architectural changes that enabled the modern data stack, from the transition from SMP to MPP, to the decoupling of storage and compute, and the rise of columnar databases, ELT workflows, and the tooling ecosystem that glues it all together.
1. From SMP to MPP
1.1 What Is SMP?
Symmetric Multiprocessing (SMP) is a legacy database architecture where multiple CPU cores share a single memory space, storage, and operating system.
- Shared resources: Memory, I/O devices, and disk are accessed through a common bus.
- Single-machine design: All computation happens on one machine.
- Scaling: Limited to vertical scaling—adding more resources to a single system.
- Performance: Great for OLTP-style workloads but restricted by hardware limits.
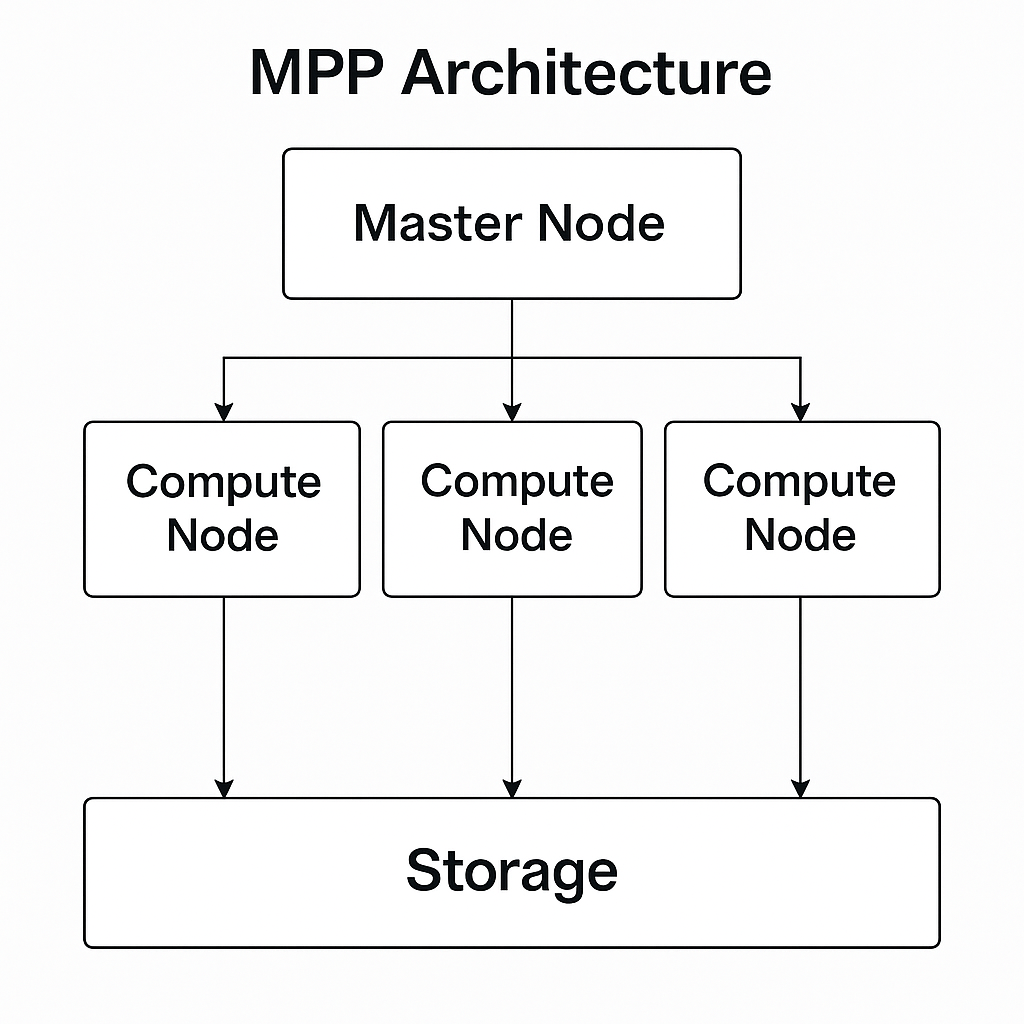
1.2 Enter MPP
Massively Parallel Processing (MPP) systems scale horizontally by distributing data and computation across many machines.
- Independent nodes: A master node coordinates multiple compute nodes.
- Parallelism: Data is sharded across nodes; each node works in parallel on its portion.
- Scaling: Add more nodes to scale out.
- Storage models:
- Shared-nothing (most common): Each node has local storage.
- Shared-storage: All nodes access a common (often cloud-based) storage layer.
Note: In cloud-native architectures, “shared storage” often refers to distributed object storage like S3, accessed independently by stateless compute nodes.
1.3 SMP vs. MPP Comparison
| Feature | SMP | MPP |
|---|---|---|
| Architecture | Single machine, shared memory | Master + multiple independent nodes |
| Scaling | Vertical only | Horizontal (scale-out) |
| Storage | Shared across cores | Local per node or shared via cloud storage |
| Parallelism | Within one machine | Across multiple machines |
| Use Case Today | Legacy on-prem systems | Modern cloud warehouses |
MPP Architecture Diagram
2. Decoupling Storage and Compute
Traditionally, storage and compute were tightly linked. Cloud platforms changed this with decoupled architecture:
- Storage: Durable, cheap, and separate (e.g., Amazon S3, GCS, Azure Blob).
- Compute: Stateless and elastic (e.g., BigQuery slots, Snowflake virtual warehouses).
Benefits
- Scale compute and storage independently.
- Pay only for compute when in use.
- Persistent storage allows compute clusters to spin down when idle.
3. Column-Oriented Databases
3.1 Row vs. Column Storage
Row-oriented databases are optimized for OLTP (e.g., inserting or updating entire records), while column-oriented databases are better for OLAP (analytical queries on large datasets).
Columnar storage allows:
- Selective column reads (reducing I/O)
- Efficient compression (similar data grouped together)
- Vectorized computation
3.2 Comparison
| Feature | Row-Oriented | Column-Oriented |
|---|---|---|
| Layout | Records stored together | Fields stored together |
| Use Case | OLTP (transactions) | OLAP (analytics, aggregations) |
| I/O Efficiency | Reads full rows | Reads only needed columns |
| Compression | Moderate | High |
| Examples | PostgreSQL, MySQL | Snowflake, Redshift, BigQuery |
4. From ETL to ELT
The traditional ETL pattern:
- Extract
- Transform
- Load
has largely been replaced by ELT:
- Extract
- Load raw data into the warehouse
- Transform it inside the warehouse
This modern pattern simplifies pipelines and leverages cloud compute.
Tradeoff: While ELT increases flexibility and auditability, it also shifts responsibility for data quality downstream—often to analytics engineers.
5. Tools in the Modern Data Stack
Each layer is served by specialized tools that integrate via APIs, JDBC/ODBC, or event systems.
| Layer | Tools | Role |
|---|---|---|
| Extract & Load | Fivetran, Airbyte, Stitch | Ingest data into warehouses from APIs, DBs, and flat files |
| Transform | DBT, Matillion, dataiku | Define SQL-based models, documentation, tests |
| Data Warehouse | Snowflake, BigQuery, Redshift | Scalable compute + storage for structured data |
| BI & Analytics | Looker, Tableau, Power BI, Metabase | Dashboards, visualization, exploration |
| Reverse-ETL | Census, Hightouch | Sync clean data from warehouse to CRMs, ads, tools |
JDBC and ODBC are protocol standards used to connect external applications to databases.
- JDBC: Java-specific
- ODBC: Language-agnostic (used by Excel, Python, R, etc.)
Modern data warehouses expose these interfaces so apps can access/query data securely.
7. Metadata & Orchestration
7.1 Orchestration Tools
Managing dependencies, schedules, and retries across the data pipeline is critical. Popular orchestration tools:
- Apache Airflow: DAG-based Python workflows
- Dagster: Strong typing + observability
- Prefect: Pythonic, cloud-native orchestration with minimal config
These tools manage the “when and how” of pipeline execution.
7.2 Metadata & Governance
Understanding what data exists, where it comes from, and who uses it is essential for modern data teams.
Popular metadata tools:
| Tool | Role |
|---|---|
| DataHub | Metadata discovery & lineage |
| Amundsen | Data catalog with search and context |
| Atlan | Collaborative metadata, governance, access |
The modern data stack is:
- Modular: Specialized tools connected via APIs
- Scalable: Independent scaling of compute/storage
- Efficient: Columnar, distributed, and cloud-optimized
Key enablers include:
- MPP architectures
- Decoupled storage/compute
- Columnar formats
- ELT processing
- Orchestration and metadata tools